centos7 部署 k8s 集群
安装docker-ce
Master、Node节点都需要安装、配置Docker
# 卸载原来的docker
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
# 安装依赖
sudo yum update -y && sudo yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
# 添加官方yum库
sudo yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
# 安装docker
sudo yum install docker-ce docker-ce-cli containerd.io
# 查看docker版本
docker --version
# 开机启动
systemctl enable --now docker
或者使用脚本一键安装
curl -fsSL "https://get.docker.com/" | sh
systemctl enable --now docker
修改docker cgroup驱动,与k8s一致,使用systemd
# 修改docker cgroup驱动:native.cgroupdriver=systemd
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
EOF
systemctl restart docker # 重启使配置生效
安装 kubelet kubeadm kubectl
master、node节点都需要安装kubelet kubeadm kubectl。
安装kubernetes的时候,需要安装kubelet, kubeadm等包,但k8s官网给的yum源是packages.cloud.google.com,国内访问不了,此时我们可以使用阿里云的yum仓库镜像。
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# 关闭SElinux
setenforce 0
sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
# 安装kubelet kubeadm kubectl
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
systemctl enable --now kubelet # 开机启动kubelet
# centos7用户还需要设置路由:
yum install -y bridge-utils.x86_64
modprobe br_netfilter # 加载br_netfilter模块,使用lsmod查看开启的模块
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system # 重新加载所有配置文件
systemctl disable --now firewalld # 关闭防火墙
# k8s要求关闭swap
swapoff -a && sysctl -w vm.swappiness=0 # 关闭swap
sed -ri '/^[^#]*swap/s@^@#@' /etc/fstab # 取消开机挂载swap
使用虚拟机的可以做完以上步骤后,进行克隆。实验环境为1 Master,2 Node
创建集群准备工作
# Master端:
kubeadm config images pull # 拉取集群所需镜像,这个需要翻墙
# --- 不能翻墙可以尝试以下办法 ---
kubeadm config images list # 列出所需镜像
# 根据所需镜像名字先拉取国内资源
docker pull mirrorgooglecontainers/kube-apiserver:v1.14.1
docker pull mirrorgooglecontainers/kube-controller-manager:v1.14.1
docker pull mirrorgooglecontainers/kube-scheduler:v1.14.1
docker pull mirrorgooglecontainers/kube-proxy:v1.14.1
docker pull mirrorgooglecontainers/pause:3.1
docker pull mirrorgooglecontainers/etcd:3.3.10
docker pull coredns/coredns:1.3.1 # 这个在mirrorgooglecontainers中没有
# 修改镜像tag
docker tag mirrorgooglecontainers/kube-apiserver:v1.14.1 k8s.gcr.io/kube-apiserver:v1.14.1
docker tag mirrorgooglecontainers/kube-controller-manager:v1.14.1 k8s.gcr.io/kube-controller-manager:v1.14.1
docker tag mirrorgooglecontainers/kube-scheduler:v1.14.1 k8s.gcr.io/kube-scheduler:v1.14.1
docker tag mirrorgooglecontainers/kube-proxy:v1.14.1 k8s.gcr.io/kube-proxy:v1.14.1
docker tag mirrorgooglecontainers/pause:3.1 k8s.gcr.io/pause:3.1
docker tag mirrorgooglecontainers/etcd:3.3.10 k8s.gcr.io/etcd:3.3.10
docker tag coredns/coredns:1.3.1 k8s.gcr.io/coredns:1.3.1
# 把所需的镜像下载好,init的时候就不会再拉镜像,由于无法连接google镜像库导致出错
# 删除原来的镜像
docker rmi mirrorgooglecontainers/kube-apiserver:v1.14.1
docker rmi mirrorgooglecontainers/kube-controller-manager:v1.14.1
docker rmi mirrorgooglecontainers/kube-scheduler:v1.14.1
docker rmi mirrorgooglecontainers/kube-proxy:v1.14.1
docker rmi mirrorgooglecontainers/pause:3.1
docker rmi mirrorgooglecontainers/etcd:3.3.10
docker rmi coredns/coredns:1.3.1
# Node端:
# 根据所需镜像名字先拉取国内资源
docker pull mirrorgooglecontainers/kube-proxy:v1.14.1
docker pull mirrorgooglecontainers/pause:3.1
# 修改镜像tag
docker tag mirrorgooglecontainers/kube-proxy:v1.14.1 k8s.gcr.io/kube-proxy:v1.14.1
docker tag mirrorgooglecontainers/pause:3.1 k8s.gcr.io/pause:3.1
# 删除原来的镜像
docker rmi mirrorgooglecontainers/kube-proxy:v1.14.1
docker rmi mirrorgooglecontainers/pause:3.1
# --- 不能翻墙可以尝试使用 ---
使用kubeadm创建集群
# 第一次初始化过程中/etc/kubernetes/admin.conf该文件存在,是空文件(我自己手多创建的),会报错:panic: runtime error: invalid memory address or nil pointer dereference
ls /etc/kubernetes/admin.conf && mv /etc/kubernetes/admin.conf{,.bak} # 移走备份
# 初始化Master(Master需要至少2核)
kubeadm init --apiserver-advertise-address 192.168.20.5 --pod-network-cidr 10.244.0.0/16 # --kubernetes-version 1.14.1
# --apiserver-advertise-address 指定与其它节点通信的接口
# --pod-network-cidr 指定pod网络子网,10.244.0.0与fannel网络对应
- 运行初始化,程序会检验环境一致性,可以根据实际错误提示进一步修复问题。
- 程序会访问https://dl.k8s.io/release/stable-1.txt获取最新的k8s版本,访问这个连接需要FQ,如果无法访问,则会使用kubeadm client的版本作为安装的版本号,使用kubeadm version查看client版本。也可以使用–kubernetes-version明确指定版本。
# 初始化结果:
[init] Using Kubernetes version: v1.14.1
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Activating the kubelet service
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Using existing etcd/ca certificate authority
[certs] Using existing etcd/server certificate and key on disk
[certs] Using existing etcd/peer certificate and key on disk
[certs] Using existing etcd/healthcheck-client certificate and key on disk
[certs] Using existing apiserver-etcd-client certificate and key on disk
[certs] Using existing ca certificate authority
[certs] Using existing apiserver certificate and key on disk
[certs] Using existing apiserver-kubelet-client certificate and key on disk
[certs] Using existing front-proxy-ca certificate authority
[certs] Using existing front-proxy-client certificate and key on disk
[certs] Using the existing "sa" key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 21.503375 seconds
[upload-config] storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.14" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --experimental-upload-certs
[mark-control-plane] Marking the node master as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node master as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: w2i0mh.5fxxz8vk5k8db0wq
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] creating the "cluster-info" ConfigMap in the "kube-public" namespace
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.20.5:6443 --token w2i0mh.5fxxz8vk5k8db0wq \
--discovery-token-ca-cert-hash sha256:65e82e987f50908f3640df7e05c7a91f390a02726c9142808faa739d4dc24252
普通用户设置权限
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
应用flannel网络
# master:
cat ~/.kube/config
# node:
# 复制master的config内容
vim ~/.kube/config # 把master的内容拷贝到node中,这样就可以在node节点中找到apiserver,使用kubectl
# master:
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
vim kube-flannel.yml # kube-flannel中添加args指定通信接口ip(可以使用正则),添加iface-regex参数,如下面的图所示(不需要使用引号引住!!!)。
kubectl apply -f kube-flannel.yml # 应用flannel网络
ps -ef | grep flannel # 确保master和node都有flannel进程,如果node节点没有flannel进程,可以尝试在node也按上述步骤apply一次。
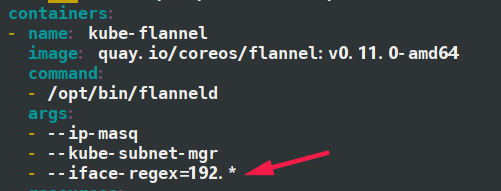
这里需要指定master与节点之间通信的接口,如果有多网卡,默认是使用默认路由的网卡,所以必须要在此明确指定,否则会导致pod相互不通的问题。
node加入机器
# 根据master初始化的提示
# node1:
kubeadm join 192.168.20.5:6443 --token w2i0mh.5fxxz8vk5k8db0wq \
--discovery-token-ca-cert-hash sha256:65e82e987f50908f3640df7e05c7a91f390a02726c9142808faa739d4dc24252
# node2:
kubeadm join 192.168.20.5:6443 --token w2i0mh.5fxxz8vk5k8db0wq \
--discovery-token-ca-cert-hash sha256:65e82e987f50908f3640df7e05c7a91f390a02726c9142808faa739d4dc24252
输出日志:
[preflight] Running pre-flight checks
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.14" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Activating the kubelet service
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
# master:
kubectl get pods --all-namespaces
# ---输出信息(全部ready才是正常的)---
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-fb8b8dccf-rn8kd 1/1 Running 0 170m
kube-system coredns-fb8b8dccf-slwr4 1/1 Running 0 170m
kube-system etcd-master 1/1 Running 0 169m
kube-system kube-apiserver-master 1/1 Running 0 169m
kube-system kube-controller-manager-master 1/1 Running 0 169m
kube-system kube-flannel-ds-amd64-l8c7c 1/1 Running 0 130m
kube-system kube-flannel-ds-amd64-lcmxw 1/1 Running 1 117m
kube-system kube-flannel-ds-amd64-pqnln 1/1 Running 1 72m
kube-system kube-proxy-4kcqb 1/1 Running 0 170m
kube-system kube-proxy-jcqjd 1/1 Running 0 72m
kube-system kube-proxy-vm9sj 1/1 Running 0 117m
kube-system kube-scheduler-master 1/1 Running 0 169m
# ---输出信息---
kubectl get nodes
# ---输出信息(全部ready才是正常的)---
NAME STATUS ROLES AGE VERSION
master Ready master 171m v1.14.1
node1 Ready <none> 118m v1.14.1
node2 Ready <none> 74m v1.14.1
# ---输出信息---
排错
# 可以在master和node节点上查看日志
journalctl -f # 当前输出日志
journalctl -f -u kubelet # 只看当前的kubelet进程日志
kubectl命令补全
source <(kubectl completion zsh) # zsh为我使用的shell,请根据实际填